字节跳动旗下的Seed团队近期公布了一项重大技术进展,他们宣布开源了一个名为BAGEL的统一多模态理解与生成模型。这一模型能够同时处理文本、图像和视频数据,实现跨模态的信息交互与生成。
据悉,BAGEL模型拥有70亿个激活参数(总参数量达到140亿),并在海量交错多模态数据上进行了深度训练。在多项标准测试中,BAGEL的表现超越了当前顶尖的开源多模态模型,如Qwen2.5-VL和InternVL-2.5,甚至在文本到图像的生成质量上,也能与专业级生成器SD3相媲美。
除了在多模态理解方面取得突破,BAGEL在图像编辑领域同样展现出了非凡的能力。它不仅在经典编辑场景中优于其他开源模型,还进一步扩展到自由形式的视觉操作、多视图合成以及世界导航等高级任务。这些能力标志着BAGEL在“世界建模”这一前沿领域迈出了重要一步。
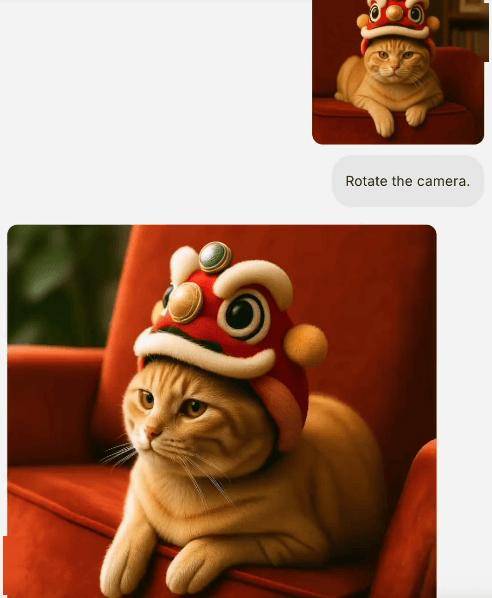
BAGEL基于先进的大语言模型进行训练,因此具备基础的推理和对话能力。它能够接收混合了图像和文本的输入,并以同样混合的格式输出结果。这种灵活性使得BAGEL在处理复杂多模态信息时更加得心应手。
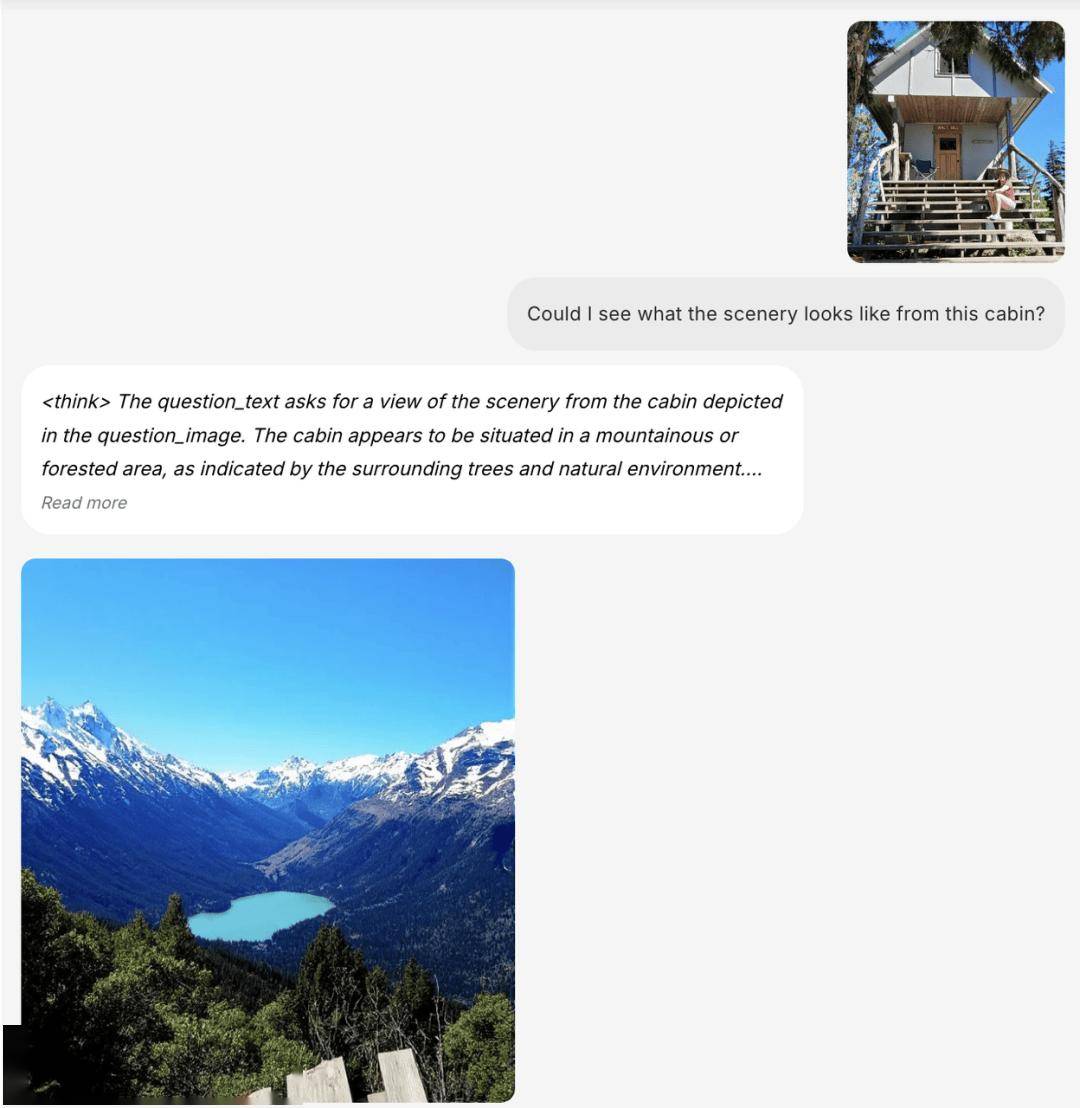
在生成高质量、逼真的图像和视频方面,BAGEL同样表现出色。它还引入了长思维链(COT)模式,使得模型在生成内容之前能够进行更为深入的“思考”。这种能力不仅提升了生成内容的质量,还增加了生成过程的可控性和可预测性。

由于在大规模交错多模态数据上的预训练,BAGEL自然而然地学会了保留视觉特征和细微细节。它能够从视频中捕捉到复杂的视觉运动,这一能力使得它在图像编辑方面更加高效且准确。BAGEL还能基于少量对齐数据实现图片风格的切换和场景转换。


更令人瞩目的是,BAGEL还具备世界模型的基础能力。它能够进行世界导航、未来帧预测以及3D世界生成等挑战性任务。通过不同角度的旋转或视角切换,BAGEL能够展现出强大的泛化能力。不仅在真实场景中表现出色,它还能在游戏、艺术作品以及卡通动画等虚拟环境中实现导航。
基于以上强大的能力,BAGEL通过一个统一的多模态接口,实现了各项能力的复杂组合和多轮对话。用户可以通过简单的指令,让BAGEL完成从图片剪切到智能编辑,再到场景转换和风格转换等一系列操作,极大地提升了工作效率和创作自由度。