在2025年6月,一场科技盛宴在美国田纳西州悄然拉开帷幕,这便是备受瞩目的国际计算机视觉与模式识别会议(CVPR2025)。此次盛会汇聚了全球顶尖的学者与科研人员,共同探讨计算机视觉领域的最新进展。
在这场科技盛宴中,一项由中国值得买科技与中国人民大学高瓴人工智能学院联手打造的科研成果《图像转有声视频》成功脱颖而出,荣耀入选CVPR2025。这项成果首次提出并实现了一种从静态图像直接生成同步音视频内容的创新框架——JointDiT(Joint Diffusion Transformer),标志着从图像到“动态视频+声音”的高质量联合生成迈出了关键一步。

CVPR,作为计算机视觉和模式识别领域的顶级年度会议,由IEEE与CVF联合主办,每年吸引着来自全球的数千名与会者。CVPR2025涵盖了从基础理论到前沿应用的广泛议题,被录用的论文代表了该领域最具影响力且经过严格同行评审的研究成果。
值得买科技与人大高瓴人工智能学院的合作始于2023年,双方结合值得买科技的集群算力、消费数据和应用场景能力,以及人大高瓴的科研和人才优势,在AI内容创作、多模态生成等方面开展前沿研究。此次的《图像转有声视频》成果,正是双方共同努力的又一力作。
长期以来,生成式模型的研究主要集中在单一模态的内容合成上,如生成高保真的视频画面或自然的音频片段。然而,在生成自然融合的有声视频时,却面临着视频和音频分离、画面和声音语义不匹配或时间上不同步等挑战。针对这一问题,JointDiT创新性地提出了图像到有声视频生成(I2SV)的新任务,并构建了统一的联合生成框架。
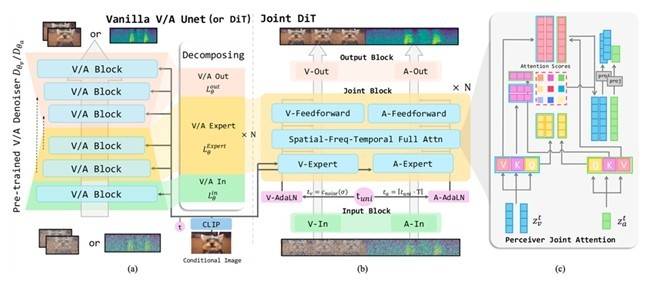
JointDiT不仅采用了“重组+协同”的创新思路,还设计了感知式联合注意力机制(Perceiver Joint Attention),实现对视频帧与音频序列之间的细粒度互动建模。同时,提出的联合无分类器引导(JointCFG)及其增强版,进一步提升了音视频之间的语义一致性与时间同步性。这一成果在视频质量、音频自然度、同步性和语义一致性等方面均实现了显著提升。
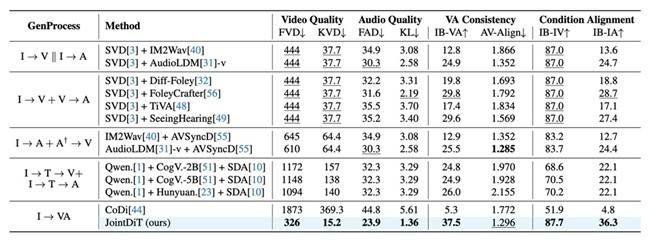
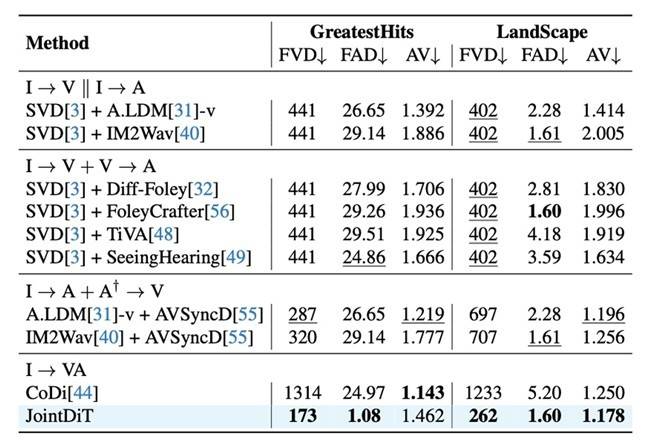
为了验证JointDiT的有效性,研究团队在三个标准数据集上进行了大量测试。结果显示,JointDiT在各项核心指标上均优于基于pipeline组合的多阶段方法。在用户主观打分测试中,JointDiT同样表现出色,在“视频质量”“音频质量”“语义一致性”“同步性”与“整体效果”五项评分中均名列前茅。
人大高瓴人工智能学院的宋睿华副教授表示,未来研究团队计划将JointDiT扩展至图像、文本、音频、视频四模态的联合建模,为构建更通用、更智能的多模态生成系统奠定基础。这一愿景无疑将为AI技术的发展注入新的活力。
值得买科技作为一家AI与内容驱动的数字消费服务集团,在AI浪潮来临之时便抢先布局,将AIGC列为集团重点战略项目。此次与人大高瓴团队的合作,正是值得买科技全面AI战略中的重要一环。据悉,双方正在制定开源计划,旨在让更多开发者能够便利地应用这一创新成果。
目前,值得买科技已形成了从技术底层、产品形态到生态共建的全面AI布局。不仅构建了以AIUC引擎为代表的底层AI技术能力,还推出了面向用户、品牌、创作者及大模型的AI产品和解决方案。同时,值得买科技还将自身沉淀的AI能力开放给合作伙伴,共建高质量AI生态,推动行业生态的繁荣与发展。